Redis数据结构_4_Ziplist
ZipList详解
[toc]
ZipList是一种特殊的双端链表,它是由一系列连续的特殊编码内存块组成,存储类型为字符串或整数。
- 可以在任意一端进行压入/弹出,且时间复杂度为O(1)
- 采用小端字节序存储
在Redis7.0后,ZipList已经被listpack替换
ZipList结构
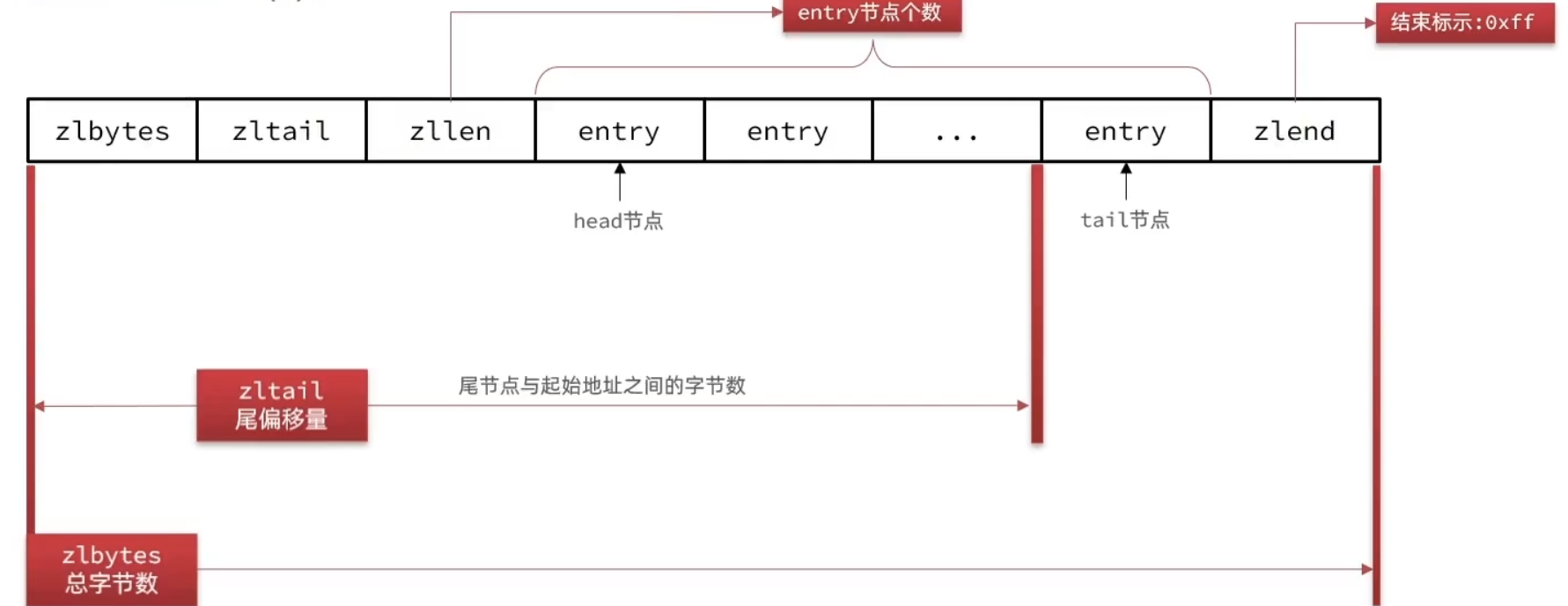
| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
| zlbytes | uint32_t | 4B | 记录整个列表占用的内存数 |
| zltail | uint32_t | 4B | 记录尾节点到列表起始地址的字节数,可以快速确定尾节点位置 |
| zllen | uint16_t | 2B | 记录列表的entry数量,如果超过表示的最大值,那么为65535,但实际个数需要遍历获得 |
| entry | 列表节点 | 不确定 | 列表的各个节点 |
| zlend | uint8_t | 1B | 特殊值0xFF,标记了列表的结束 |
- 由于0xFF是结束标志,因此其他entry都不以0xFF开头。
ZipList Entry结构
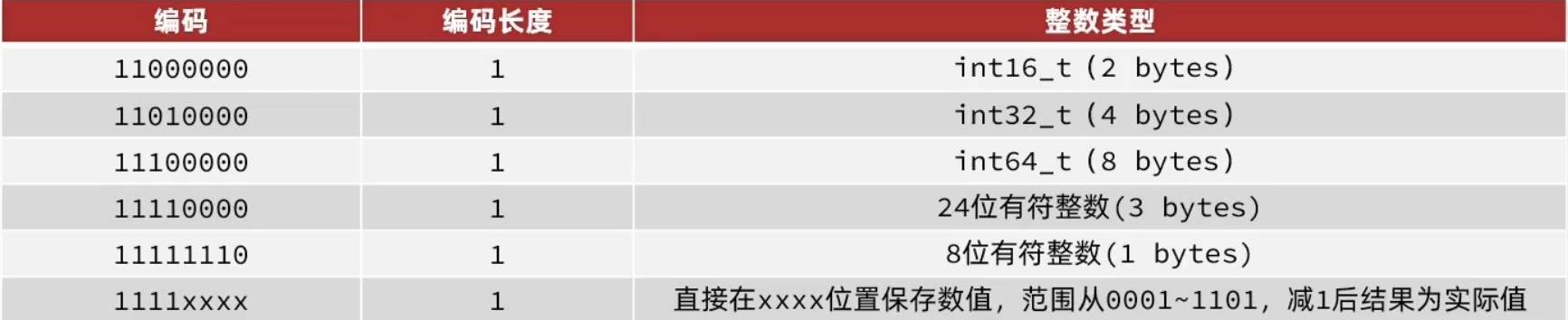
prevlen:前一节点的总长度,占1或5字节
- 如果前一个节点小于254字节,用1个字节保存
- 大于等于254字节,用5个字节保存
encoding:记录了content的数据类型(字符串或整数)以及entry-data的长度
如果encoding以00,01,10开头,证明存储的是字符串

11开头存储的就是整数,此时encoding固定占用1个字节
entry-data:保存实际的数据
通过上述文字,我们可以知道zipList的遍历方式:
- 从前向后遍历:
next_index = base_index + len(prevlen) + len(encoding) + len(entry-data) - 从后向前遍历:
last_index = base_index - prevlen
ZipList示例
字符串示例
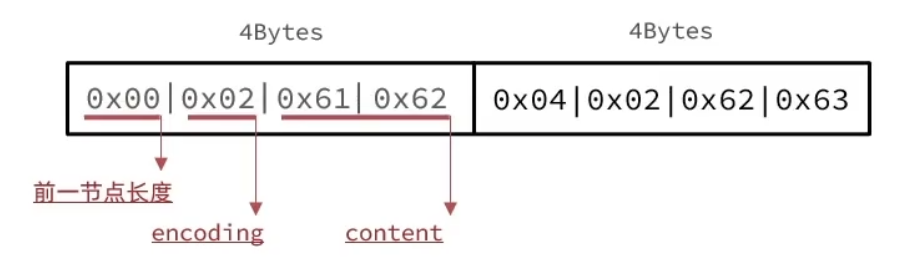
假设我们现在存储字符串”ab”和”bc”
对于字符串ab,由于没有上一个节点,因此prevlen用一个字节保存,为0x00;因为len("ab") = 2B <63B,所以encoding为0x02;
entry-data = 0x6162 (0x61 = 97, 0x62 = 98,是a和b的ASCII值)
因此第一个节点为0x00 02 61 62,同理可得第二个节点为0x04 02 62 63,如图所示:
此时,zllen = 2 = 0x02 00;
zltail = 14 = 0x0e 00 00 00;
zlbyte = 19 = 0x13 00 00 00; 注意:ZipList采用小端序存储

整数示例
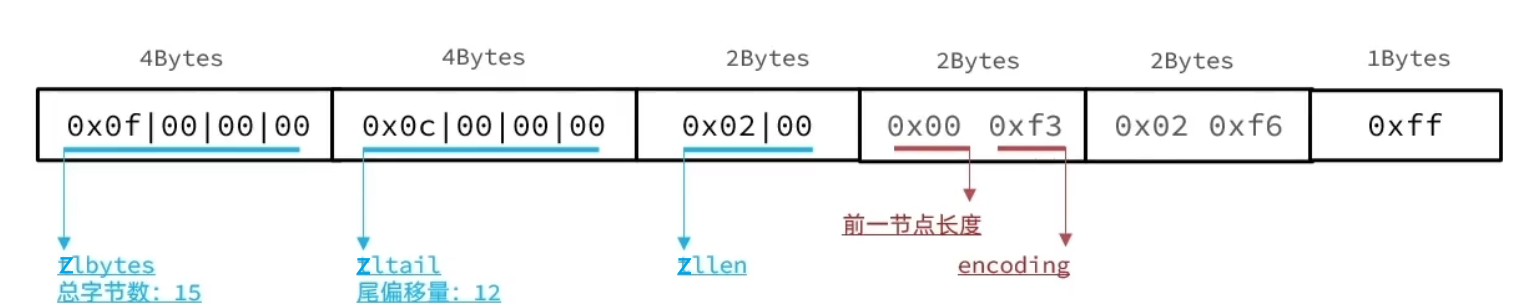
假设我们现在存储整数2和5.
对于数字2和5,由于它们都很小,处在0~12中,因此采用整数的最后一种编码,取消entry-data部分。
第一个数字2没有前结点,prevlen = 0 = 0x 00;encoding = 1111 0011 = 0xF3,同理可得第二个节点5编码为 0x 02 f6
其他zlbytes 、zltail 、 zllen 推算同字符串部分中的推算过程,最终得到的存储结构如下:
可以看出,ZipList各种各样的编码都是为了尽可能节省内存空间。
也因此,它压缩了空间,使得只能进行正序或逆序遍历来访问节点,所以它不适合存储大量节点,需要对节点数量进行限制。
ZipList的连锁更新问题
前文说过ZipList的Entry有prevlen保存前一个节点的长度,且它的大小为1或5个字节。
- 如果前一个节点长度小于254字节,那么prevlen为1个字节
- 如果前一个节点长度大于等于254字节,那么prevlen为5个字节
假设现在有N个连续,长度在250-253个字节的entry,此时它们的prevlen都是1个字节保存,如图:

此时,表头插入了一个长度为254字节的entry,它的下一个节点的prevlen部分就会从1个字节变为5个字节,也使得下一个节点的长度+4,达到了254字节,因此下下个节点的prevlen也会从1字节变为5字节,依次类推,最终产生了连锁反应,导致了连续多次的空间拓展。而扩展涉及到内存的申请、分配、数据迁移等,因此涉及了用户态和内核态的切换,严重影响效率。
这就是连锁更新问题,新增和删除都可能导致连锁更新问题的产生。
- 当然可以看出,该问题实际发生的概率很低



