Dict详解 [toc]
Dict:一个key-value型的数据结构。我们知道Redis就是键值对型的数据库,它正是基于Dict来实现的。
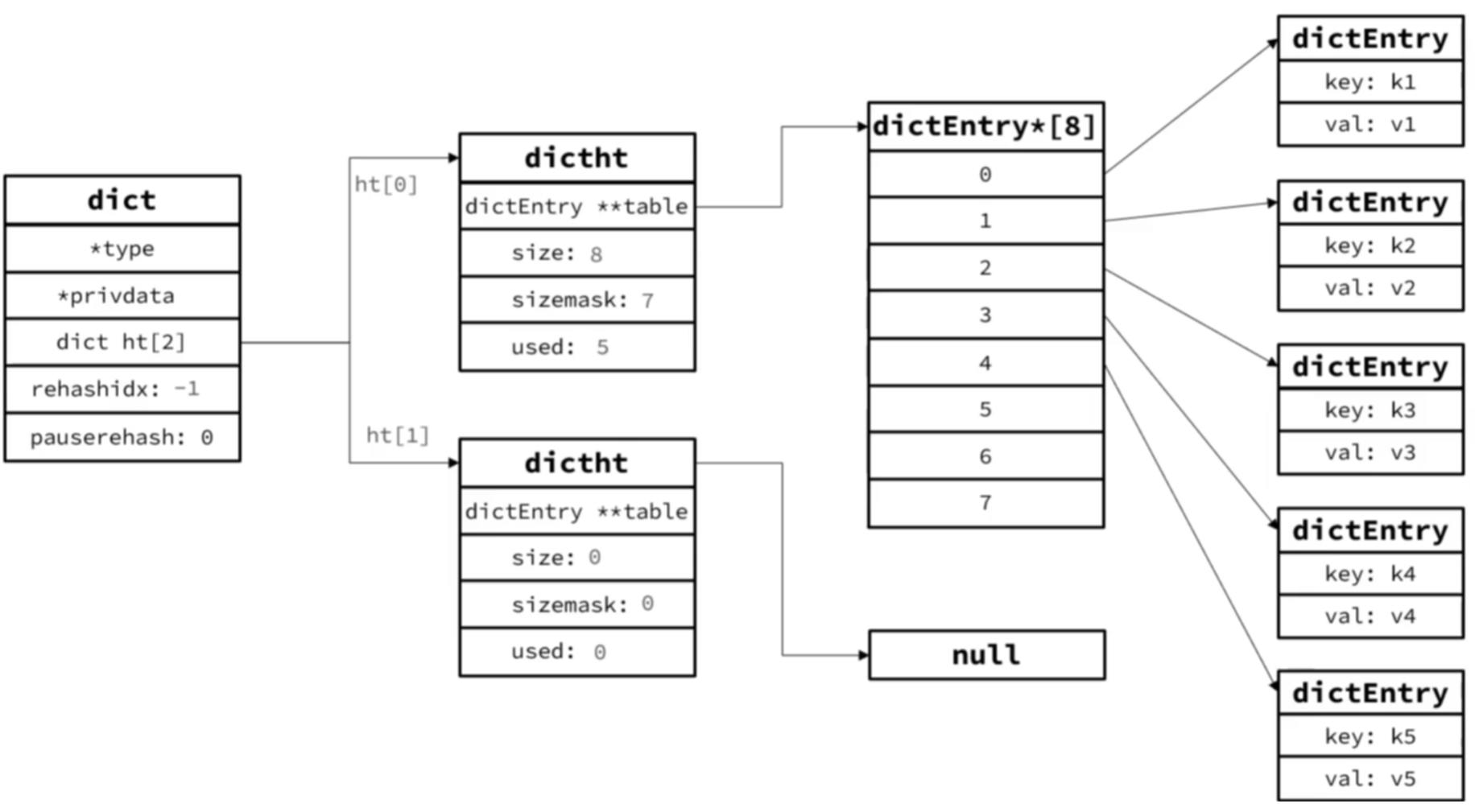
Dict和Entry结构体 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 struct dict { dictType *type; dictEntry **ht_table[2 ]; unsigned long ht_used[2 ]; long rehashidx; unsigned pauserehash : 15 ; unsigned useStoredKeyApi : 1 ; signed char ht_size_exp[2 ]; int16_t pauseAutoResize; void *metadata[]; };
Entry:键值对,v是联合体中的任意一种
1 2 3 4 5 6 7 8 9 10 struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next ; };
Dict添加规则 当向Dict中添加键值对时,Redis首先根据key计算出哈希值h,然后通过h & sizemask计算应该存储到的索引,如果发生冲突,那么采用拉链法解决冲突问题。
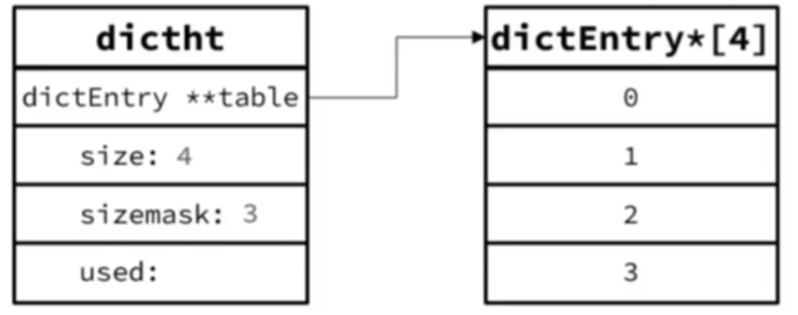
流程示例 Dict初始大小为4,如图:
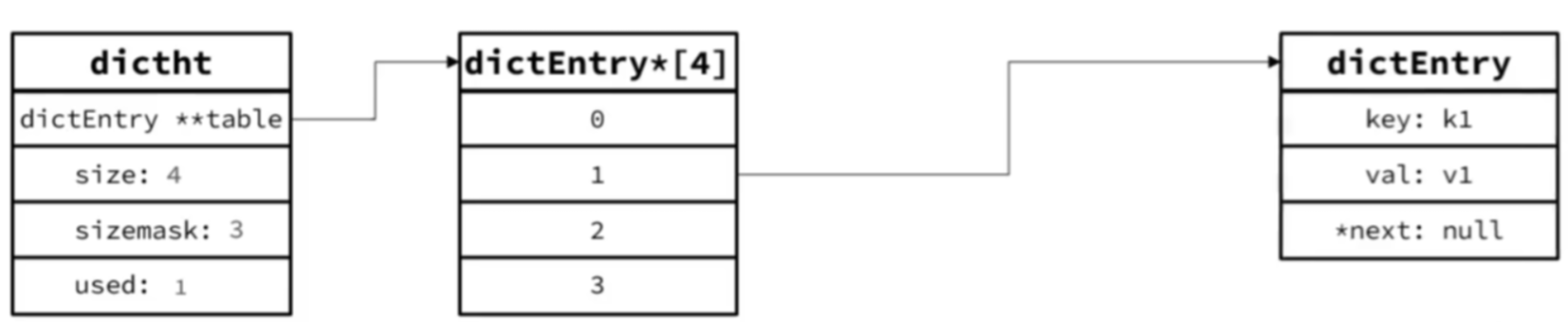
插入第一个元素,假设hashcode(k1) = 1 => 1 & 3 = 1,因此存储到下标1处,如图
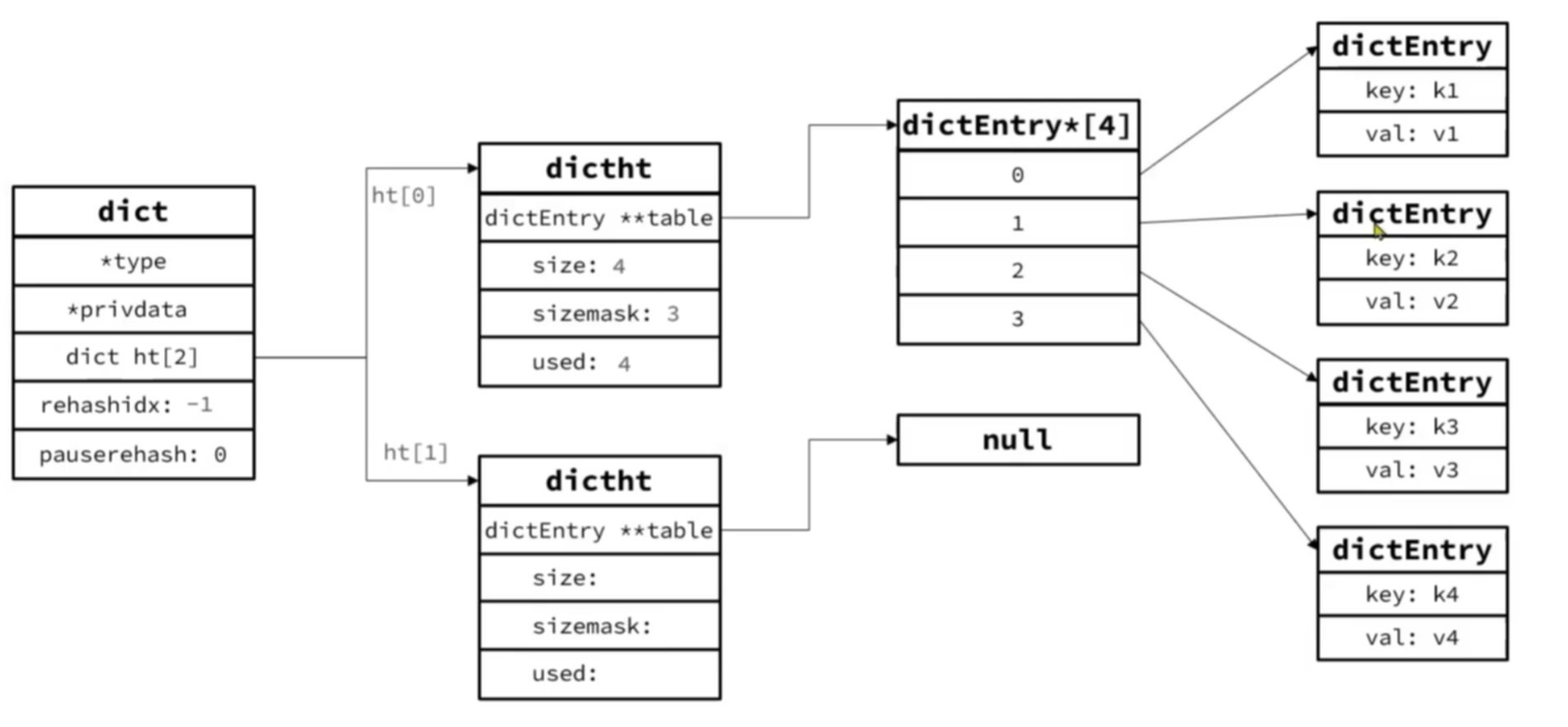
插入第一个元素,假设hashcode(k2) = 1 => 1 & 3 = 1,因此发生哈希冲突,采用拉链法存储到下标1处,如图
Dict扩容 Dict在每次新增键值对时都会去检查负载因子loadFactor = used / size,满足以下两种情况时进行扩容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int dictExpandIfNeeded (dict *d) { if (dictIsRehashing(d)) return DICT_OK; if (DICTHT_SIZE(d->ht_size_exp[0 ]) == 0 ) { dictExpand(d, DICT_HT_INITIAL_SIZE); return DICT_OK; } if ((dict_can_resize == DICT_RESIZE_ENABLE && d->ht_used[0 ] >= DICTHT_SIZE(d->ht_size_exp[0 ])) || (dict_can_resize != DICT_RESIZE_FORBID && d->ht_used[0 ] >= dict_force_resize_ratio * DICTHT_SIZE(d->ht_size_exp[0 ]))) { if (dictTypeResizeAllowed(d, d->ht_used[0 ] + 1 )) dictExpand(d, d->ht_used[0 ] + 1 ); return DICT_OK; } return DICT_ERR; }
需要注意的是,哈希表大小始终是$2^n$,因此扩容会扩到满足条件且容量是$2^n$。
Dict收缩 Dict在删除元素时,也会检查负载因子,当loadFactor<0.125且允许resize时,触发哈希表收缩。或者当loadFactor<1/32,且resize未被禁止时收缩。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int dictShrinkIfNeeded (dict *d) { if (dictIsRehashing(d)) return DICT_OK; if (DICTHT_SIZE(d->ht_size_exp[0 ]) <= DICT_HT_INITIAL_SIZE) return DICT_OK; if ((dict_can_resize == DICT_RESIZE_ENABLE && d->ht_used[0 ] * HASHTABLE_MIN_FILL <= DICTHT_SIZE(d->ht_size_exp[0 ])) || (dict_can_resize != DICT_RESIZE_FORBID && d->ht_used[0 ] * HASHTABLE_MIN_FILL * dict_force_resize_ratio <= DICTHT_SIZE(d->ht_size_exp[0 ]))) { if (dictTypeResizeAllowed(d, d->ht_used[0 ])) dictShrink(d, d->ht_used[0 ]); return DICT_OK; } return DICT_ERR; }
最终Dict扩容和收缩最终都由_dictResize函数来完成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 int _dictResize(dict *d, unsigned long size, int * malloc_failed){ if (malloc_failed) *malloc_failed = 0 ; assert(!dictIsRehashing(d)); dictEntry **new_ht_table; unsigned long new_ht_used; signed char new_ht_size_exp = _dictNextExp(size); size_t newsize = DICTHT_SIZE(new_ht_size_exp); if (newsize < size || newsize * sizeof (dictEntry*) < newsize) return DICT_ERR; if (new_ht_size_exp == d->ht_size_exp[0 ]) return DICT_ERR; if (malloc_failed) { new_ht_table = ztrycalloc(newsize*sizeof (dictEntry*)); *malloc_failed = new_ht_table == NULL ; if (*malloc_failed) return DICT_ERR; } else new_ht_table = zcalloc(newsize*sizeof (dictEntry*)); new_ht_used = 0 ; d->ht_size_exp[1 ] = new_ht_size_exp; d->ht_used[1 ] = new_ht_used; d->ht_table[1 ] = new_ht_table; d->rehashidx = 0 ; if (d->type->rehashingStarted) d->type->rehashingStarted(d); if (d->ht_table[0 ] == NULL || d->ht_used[0 ] == 0 ) { if (d->type->rehashingCompleted) d->type->rehashingCompleted(d); if (d->ht_table[0 ]) zfree(d->ht_table[0 ]); d->ht_size_exp[0 ] = new_ht_size_exp; d->ht_used[0 ] = new_ht_used; d->ht_table[0 ] = new_ht_table; _dictReset(d, 1 ); d->rehashidx = -1 ; return DICT_OK; } return DICT_OK; }
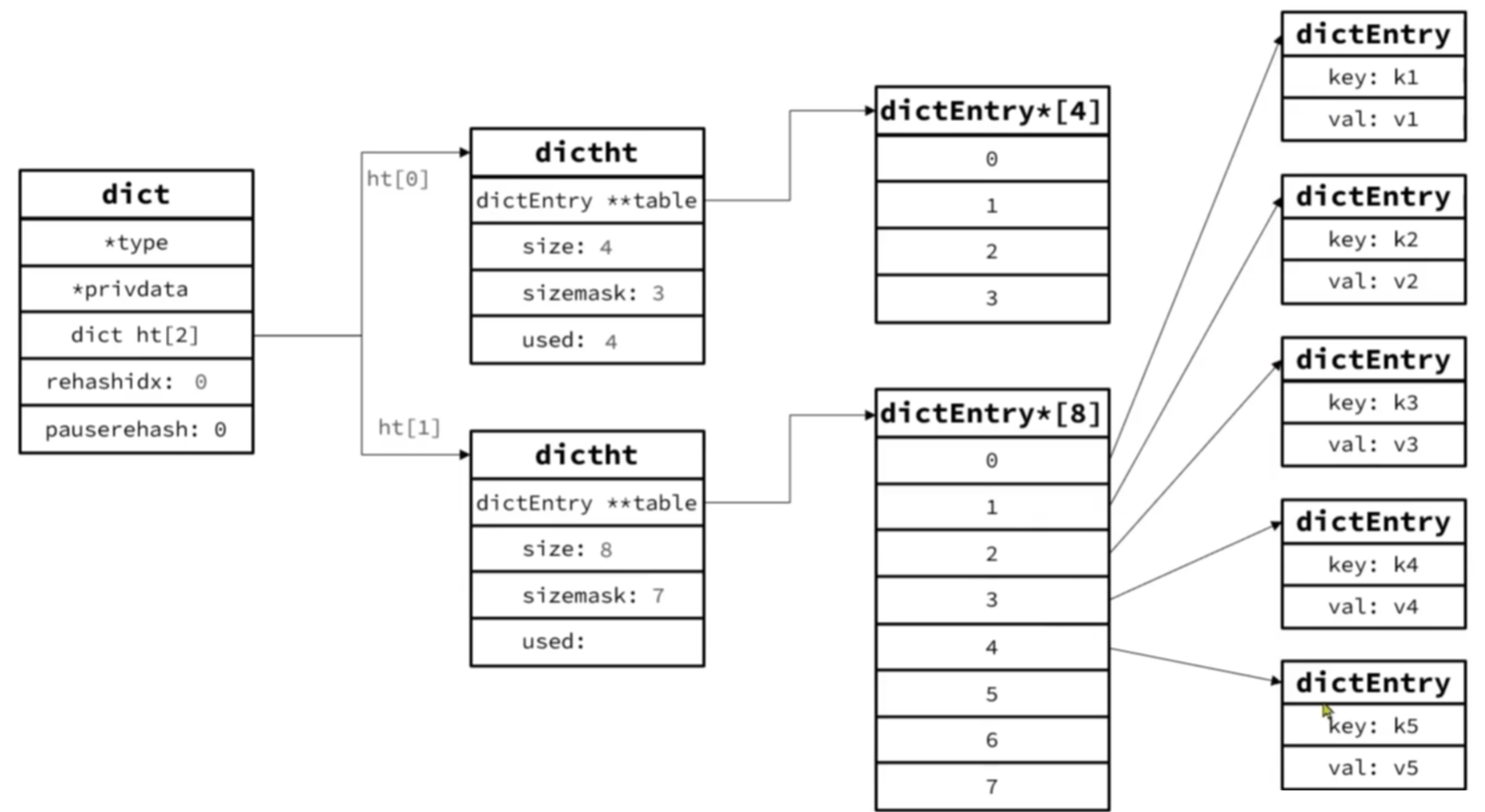
Dict的Rehash 示例如下:一个哈希表容量为4,并且已经装载了4个键值对,即将插入第五个,触发了扩容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 int dictRehash (dict *d, int n) { int empty_visits = n*10 ; unsigned long s0 = DICTHT_SIZE(d->ht_size_exp[0 ]); unsigned long s1 = DICTHT_SIZE(d->ht_size_exp[1 ]); if (dict_can_resize == DICT_RESIZE_FORBID || !dictIsRehashing(d)) return 0 ; if (dict_can_resize == DICT_RESIZE_AVOID && ((s1 > s0 && s1 < dict_force_resize_ratio * s0) || (s1 < s0 && s0 < HASHTABLE_MIN_FILL * dict_force_resize_ratio * s1))) { return 0 ; } while (n-- && d->ht_used[0 ] != 0 ) { assert(DICTHT_SIZE(d->ht_size_exp[0 ]) > (unsigned long )d->rehashidx); while (d->ht_table[0 ][d->rehashidx] == NULL ) { d->rehashidx++; if (--empty_visits == 0 ) return 1 ; } rehashEntriesInBucketAtIndex(d, d->rehashidx); d->rehashidx++; } return !dictCheckRehashingCompleted(d); }
值得注意的是,Dict的rehash不是一次完成的,如果Dict含有大量元素,那么一次性完成将会造成长时间的阻塞。因此Dict的rehash是多次、分批完成的,也叫作渐进式rehash。
每次增删改查时都会检查是否已经rehash完成,如果未完成则进行一部分的迁移。
在新增时,直接写入新表,而查、改、删会查询两个表,确保旧表数据只减不增,最终能完成rehash任务。